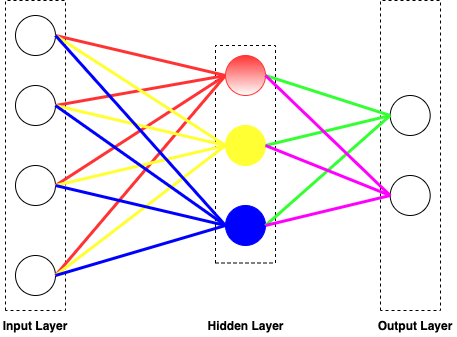
Linear Function
Let’s say we decide to approximate y as a linear function of x
hθ(x)=θ0∗x0+θ1∗x1+...+θn∗xn=i=0∑nθi∗xi=⎝⎜⎜⎜⎛θ0θ1...θn⎠⎟⎟⎟⎞T∗⎝⎜⎜⎜⎛x0x1...θn⎠⎟⎟⎟⎞
where the θi’s are the parameters (also called weights) parameterizing the space of linear functions mapping from X to Y, θ and x are both n∗1 vectors
In case of a collection of dataset x and y, let’s say xj and yj is the jth data, the linear function can be written as
Hθ(X)=⎝⎜⎜⎜⎛y0y1...yn⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛θ0∗x00+θ1∗x10+...+θn∗xn0θ0∗x01+θ1∗x11+...+θn∗xn1...θ0∗x0m+θ1∗x1m+...+θn∗xnm⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛∑i=0nθi∗xi0∑i=0nθi∗xi1...∑i=0mθi∗xim⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛x00,x10,...,xn0x01,x11,...,xn1...x0m,x1m,...,xnm⎠⎟⎟⎟⎞∗(θ0,θ1,...,θn)T=X∗θ