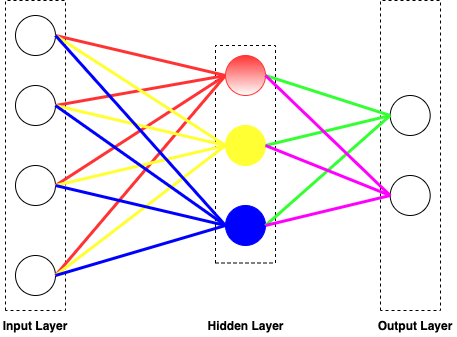
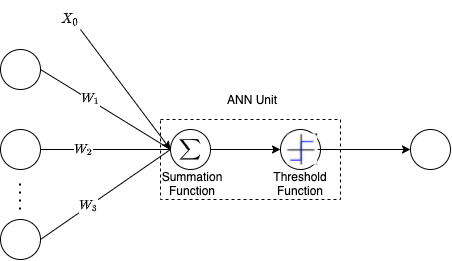
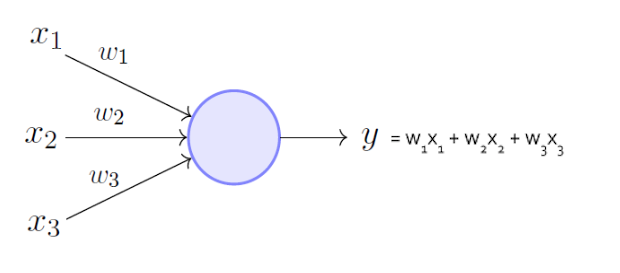
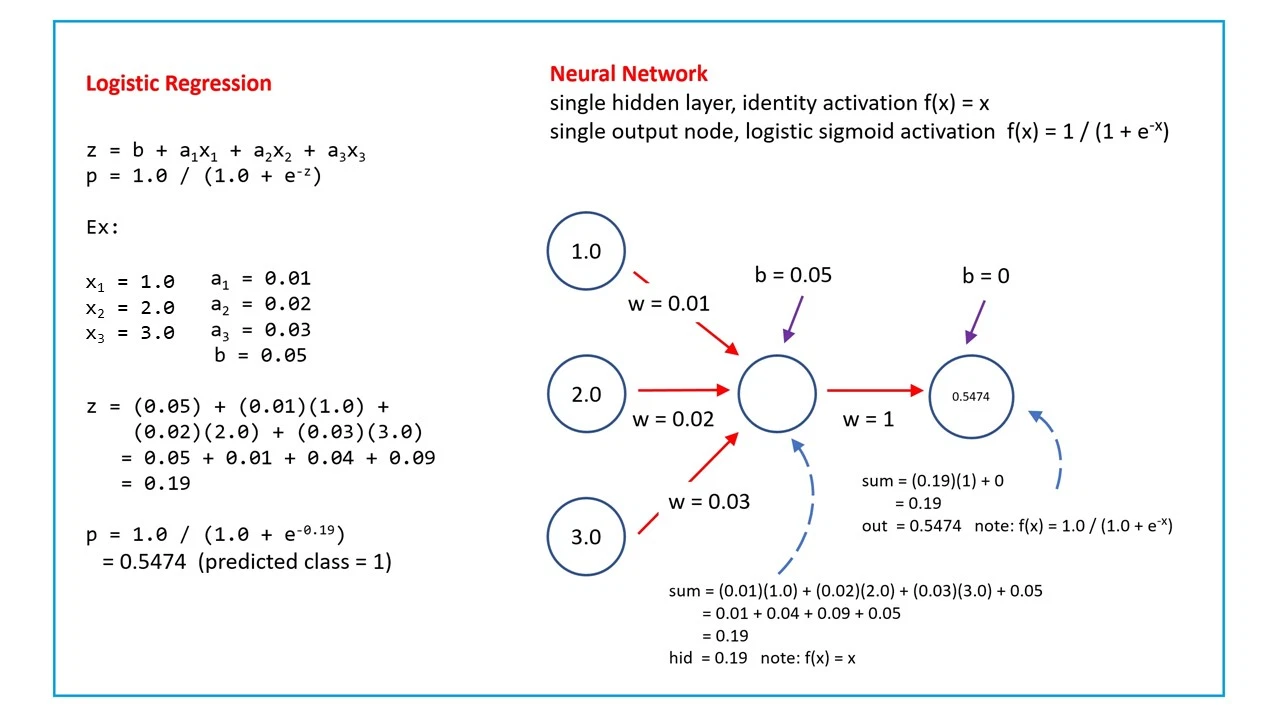
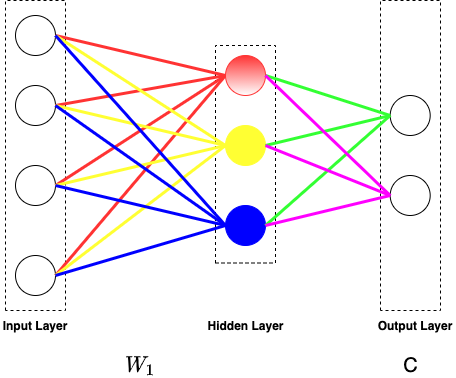
Artificial Neural Networks (ANNs) are loosely modeled after the brain. ANNs are composed of units (also called nodes) that are modeled after neurons, with weighted links interconnecting the units together.
What ANN?
Overall, the ANN contains input layer, hidden layer and the output layer.
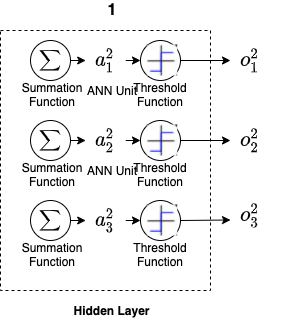
Each hidden layer has an input, an output and a number of ANN units while the ANN unit is composed of two main parts: the first part sums the input and sends it to the threshold function.
If the activation is greater than 0 then the unit activates and sends a “1” as the output, otherwise it sends a 0 (or –1). The X0 can be set to any value so that instead of tuning the threshold function to activate at some fixed point Y, X0 can be set to -Y.
Why ANN?
Can approximate any function(when target function is not known)
Is a superset of a logistic regression(when output is a vector of continuous or discrete values)
Forward Propagation
Let’s take one ANN unit out from the ANN. From the defintion, an ANN unit is a composition of a summation function and a threshold function(a.k.a activation function). Before describing the forward propagation, let’s define some terms and defintions.
Threshold Function
For each ANN unit, the summation result will be passed to a thresold function for an output. Let’s say aik is the ith input in the kth layer and the corresponding output is oik. Below is an example of input and output in layer #2
A vector can be used to describe all scalar input/output in the same layer.
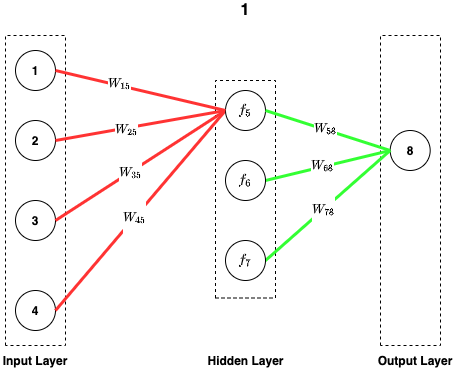
Weight is the connection between each layer and its previous layer. Below is an example of weights in a 3-layer ANN.
If we’d like to calculate the input of node #5, we will need to sum up four input node with its weight. Let’s say oi is the ith input node, wi5 is the weigth between node #1 and #5.
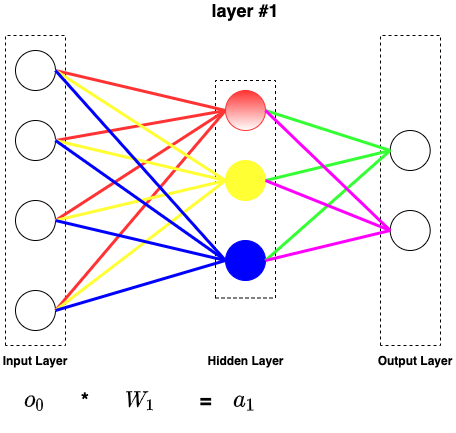
Put all nodes in the layer#1 together will give us a more complex matrix expression. Take o0 as input, a1 be the output of the summation(input to threshold function in layer #1)
Every layer follows the same pattern, then we have our second formula,
Define Wk be the weight matrix of kth layer, ok−1 be the output from the previous layer, and ak be the output of summation(input to layer #k)
Wk∗ok−1=ak(2)
Forward Propagation Algorithm
Let’s have a quick recap on two important formula from the previous section,
ok=f(ak)(1)
Wk∗ok−1=ak(2)
The formula #1 changes a to o while formula #2 push result to the next layer.
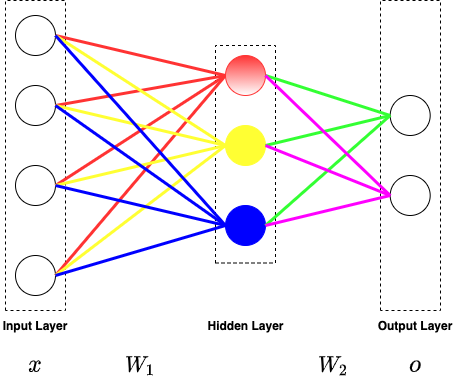
With the input x and the weight matrix W, we can calculate the output easily by using formula #1 and formula #2
o=f(W2f(W1x)
Back Propagation
The back propagation is an algorithm to update the weight in order to minimize the difference between the expected output and the actual output from forward propagation in the training set.
Goal
Let’s define loss function first. Usually we use distance between expected output and the actual output. Say that o is the output calculated from forward propagation while y is the expected output from the training set.
C=21(o−y)2
Our goal is to minimize the C by updating W in each layer. What we usually do is gradient descent.
Wk=Wk−η∂Wk∂C(3)
The question is how to find the connection of W1 with C(and W2 with C)
Chain Rule
Since C is the function of o, C=21(o−y)2, o is the function of a, ok=f(ak) and a is the function of W, Wk∗ok−1=ak, we can transfer the partial derivative of C with W into with a by chain rule.
∂Wk∂C=∂ak∂C∂Wk∂ak
From formula {2}, Wk∗ok−1=ak
∂Wk∂ak=∂Wk∂Wk∗ok−1=ok−1T
The next step is to find out ∂ak∂C
Error Term
Let’s define error term as
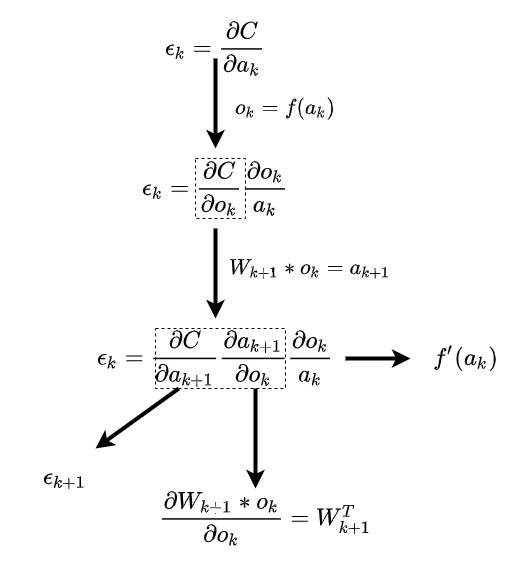
ϵk=∂ak∂C
It doesn’t seem like we can calculate ϵk directly, but what if we know ϵk+1
From formula #1 and #2,
ok=f(ak)(1)
Wk+1∗ok=ak+1(2)
we can transfer our original task to the following equation by chain rule
Back Propagation Algorithm
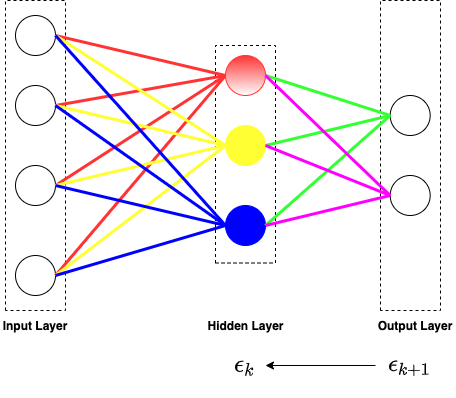
The BP algorithm is calculated in a reverse direction compared to the forward propagation. The algorithm is described as follows,
For each layer k from the right to left,
calculate the error term by the error rate of k+1 layer.
ϵk=ϵk+1Wk+1Tf′(ak)
The rightmost layer(output layer) error term, y’ is the actual output while y is the expected output
ϵ=(y′−y)f′(ak)
update the weights by the error term and output of k layer
Wk=Wk−ηϵkok
XOR Problem
The XOr, or “exclusive or”, problem is a classic problem in ANN research. It is the problem of using a neural network to predict the outputs of XOr logic gates given two binary inputs. An XOr function should return a true value if the two inputs are not equal and a false value if they are equal.
Traning Set
All possible inputs and predicted outputs are shown below.
Input 1
Input 2
Output
0
0
0
0
1
1
1
0
1
1
1
0
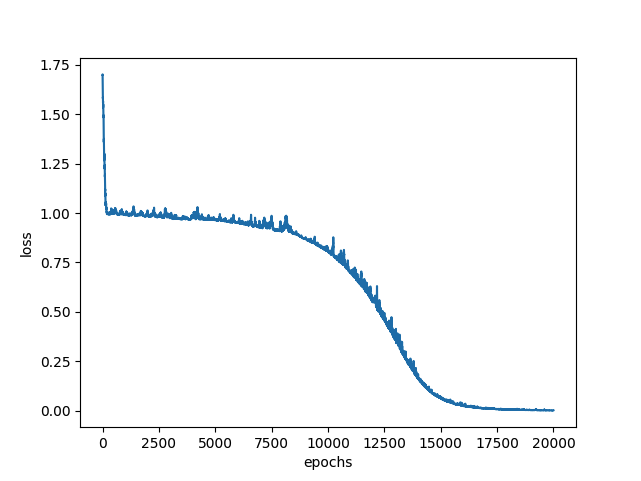
Traning ANN
2 dimensional inputs with 1 dimensional output(binary classification) and 1 hidden layer with 2 ANN units.